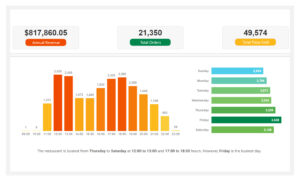
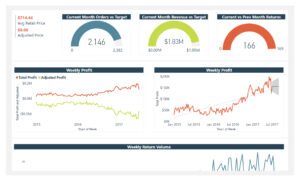
Data sets often come with missing values. The problem of missing data is relatively common and can significantly affect the conclusions drawn from your data. There can be several reasons why some values are missing from the data. Investigating these missing values and how they are recorded in the data is essential for every analysis.
In many cases, we can not simply remove missing values, because we need enough data for meaningful analysis. Although there is no single accepted solution, It is often helpful to look at the context of the problem and dig deeper into causes and plan your solution for missing values.
What are missing values?
The following values are considered missing values.
| Null |
| NA |
| N/A |
| #N/A |
| NaN |
| “-” |
| “Invalid” |
| Blank |
How to handle missing values?
We can use a number of strategies to handle missing data. However, these are the most common methods.
Remove
The first common method to deal with missing data is to delete the rows with missing values. However, it is not always possible to simply delete the data as this can lead to loss of information. Therefore, before removing data, It is important to confirm that there is no pattern or bias in the missing values. This method is not useful when the data set is too small.
Keep
Missing values may themselves can be informative. If a dataset is small, removing data can reduce statistical power. Therefore, try to keep as much data as possible if you are certain that they are accurate. If a value is missing because it doesn’t exist, there’s no point in guessing what it is, so you should leave the missing value as zero.
Impute
Imputing or guessing a value is one of the most common methods when dealing with missing data because it wasn’t recorded. In some cases, we can fill in the missing values with zeros (0). However, filling missing values with zeros is often not a good idea, as the original missing value may be something else. The zeros can cause misinterpretation of the data. Alternatively, we could use the mean or median of the existing observations, or a smart guess from some interpolation. We can use observations from similar data points to intelligently guess the value. In most cases, imputation methods can provide fairly reliable results, depending on why the data are missing.
Of course, there more options for dealing with missing values. It is important to understand and choose the right options because missing values can have a huge impact on the final results.
What other methods do you recommend or use to process your data? Let me know in the comments section.